Main pipeline¶
By selecting a limited urbanized area and a list of online communities in a social network, it is possible to run this dataset across all major library functions. However, in some cases, the order in which they are run is important.
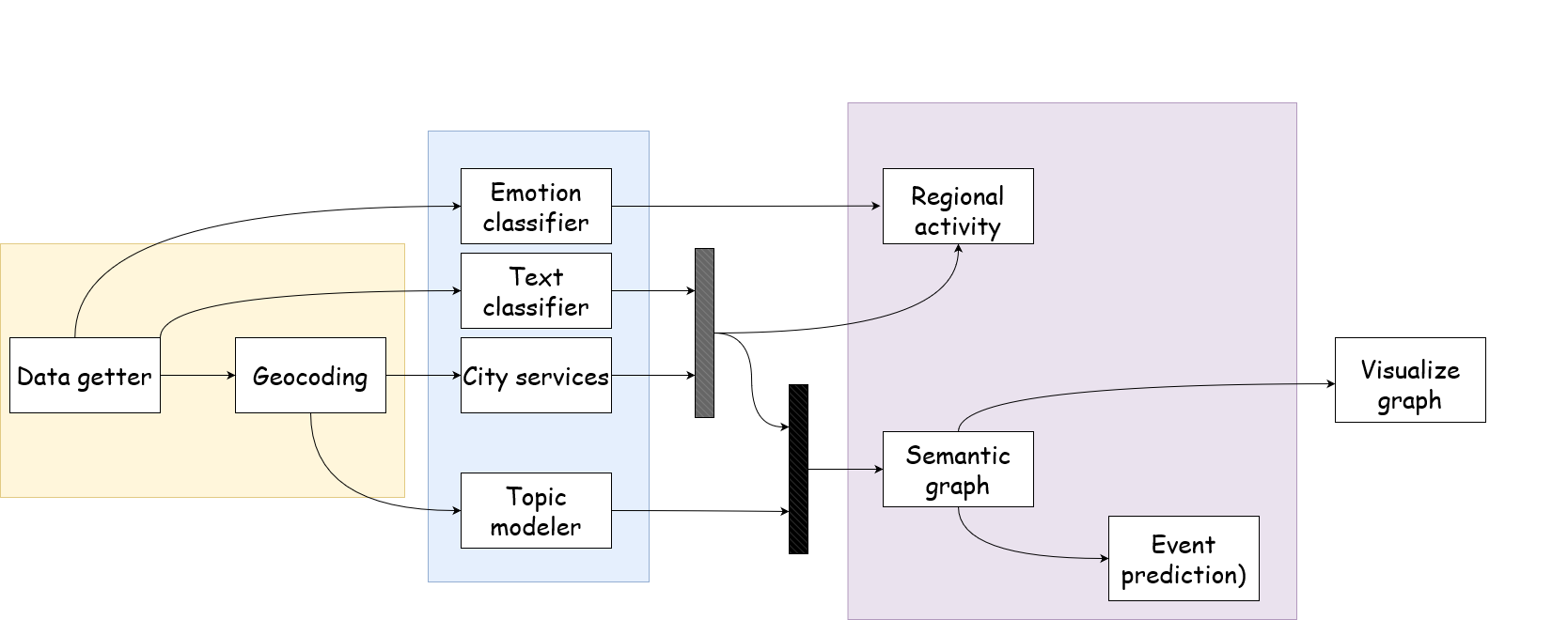
SOIKA’s sections¶
The main sections were divided into: * Data receiving (a step possible to skip only if there is already geolocated text data mentioning urban sites, otherwise the steps are very important - Data getter and Geocoding )
Data tagging: Characterization of messages and urban objects, which can be carried out in any order: Emotion classifier Text Classifier Services extraction Topic Modelling
Data modelling: Section consists of further synthesis of the obtained data, risk assessment and forecasting. Each of the methods in this group requires certain labeling columns: Semantic graph Regional activity
Data visualization: The last step is applied to the already generated semantic graph - Graph visualization
You can get more info about each step in!